Lyric Intelligibility Baseline
A. Overview
Challenge entrants are supplied with a fully functioning baseline system, which is illustrated in Figure 1.
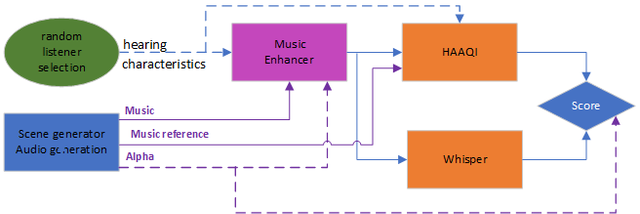
Figure 1. The Lyric Intelligibility Baseline
Click here for overview of Figure 1
- A scene generator (blue box):
- Selects the stereo music signal.
- Gives a value of (metadata) that sets the balance between intelligibility and audio quality (see evaluation below).
- The music enhancement stage (pink box) takes the music as inputs and attempts to improve the intelligibility.
- Listener characteristics (green oval) are audiograms and compressor settings to allow personalised processing in the enhancement stage and are also used in objective evaluation.
- The enhancement outputs are evaluated using objective metrics (orange boxes):
- For intelligibility using a metric based on Whisper (correct transcribed words ratio).
- For audio quality via the Hearing-Aid Audio Quality Index (HAAQI) [1].
Your challenge is to improve what happens in the pink, music enhancement box. The rest of the baseline is fixed and should not be changed.
B. Music Enhancer
Figure 2 shows the music enhancer supplied in the baseline. Your task is to improve this.
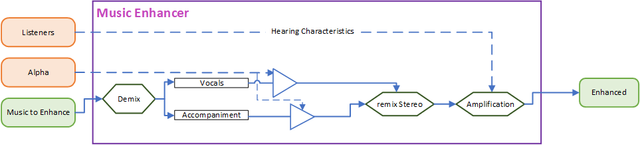
Figure 2. The Baseline Music Enhancer
The baseline approach is to demix the stereo music into vocals and instrumentation. To change intelligibility we apply amplification to the vocals and accompaniment before recombining the signals. The final stage is to apply a frequency-dependent amplification to correct for the hearing loss.
Demixing uses Conv-TasNet [1] as this can be used in either a causal and non-causal form. The overall architecture is Fig 1A in reference [1], encoder-separator-decoder. The implementation is a fully convolutional system.
Linear gains are applied to the vocals () and accompaniment () using the following formulations:
where = , the balance parameter given in the metadata. Eqns (1) and (2) were chosen so for =0 the gains are 0 dB for both the vocals and the accompaniment so the original mix is achieved, and for =1 only the vocals remain, which ought to be maximum intelligibility. A quadratic function was empirically chosen to reduce the gain difference between vocals and accompaniment for low values.
Remixing to stereo This is a sum of the amplified vocals and accompaniment.
Amplification is a simulation of hearing-aid non-linear amplification - see amplification for more details.
Output is FLAC format 16-bit, 44.1 kHz.
C. Objective Evaluation
C.1 Intelligibility
The enhanced audio is first passed through the MSBG hearing loss simulator in the pyClarity codebase [2]. It is then passed through the Whisper ASR algorithm (size: base) [3] to gain a text transcription. The objective score will be the transcription correctness computed as the ratio of correct transcribed words compared to the correct transcript of the lyrics.
C.2 Quality
The enhanced audio is evaluating using the HAAQI implementation in pyClarity. This is an intrusive metric and requires a reference. The reference signal is the original stereo track but with the vocals amplified by 1 dB and the accompaniment attenuated by 1 dB. This is done because research shows a small amplification of lyrics is preferred by people with hearing loss [5]. The reference is also amplified using a simulation of a simple hearing-aid - see amplification for more details.
C.3 Overall score
To rank the teams, the intelligibility LI and quality Q ratings are combined as follows:
D. Baseline Results
The average validation set scores computed:
- HAAQI: average of all average left and right scores
where:
= haaqi score for left ear
= haaqi score for right ear
= total number of samples to evaluate
- Correctness: average of correctness of each sentence computed as the sum of correct transcribed words over the total words in the sentence for the better ear.
where:
= number of correct transcribed words in sentence for left ear
= number of correct transcribed words in sentence for right ear
= correct transcribed words in sentence for the better ear
= total number of words in sentence
= total number of samples to evaluate
-
Overall: See section C.3 Overall Score above
-
Z Normalized: Z normalized HAAQI and Correctness scores per sample before computing the Overall score
| Baseline | HAAQI | Correctness | Overall | Z Normalized |
|---|---|---|---|---|
| Causal | 0.7755 | 0.3744 | 0.6549 | 0.2676 |
| NonCausal | 0.7841 | 0.3887 | 0.6737 | 0.2782 |
References
[1] Luo, Y. and Mesgarani, N., 2019. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM transactions on audio, speech, and language processing, 27(8), pp.1256-1266.
[2] Tu, Z., Ma, N. and Barker, J., 2021. Optimising hearing aid fittings for speech in noise with a differentiable hearing loss model. arXiv preprint arXiv:2106.04639.
[3] Radford, A., Kim, J.W., Xu, T., Brockman, G., McLeavey, C. and Sutskever, I., 2023, July. Robust speech recognition via large-scale weak supervision. In International conference on machine learning (pp. 28492-28518). PMLR.
[4] Kates, J. M., & Arehart, K. H. (2015). The hearing-aid audio quality index (HAAQI). IEEE/ACM transactions on audio, speech, and language processing, 24(2), 354-365.
[5] Benjamin, A.J. and Siedenburg, K., 2023. Exploring level-and spectrum-based music mixing transforms for hearing-impaired listeners. The Journal of the Acoustical Society of America, 154(2), pp.1048-1061.